

碎碎念
耗时三四天左右,前天折腾的AI生成视频现在是完全失败了,原因吗,当然也是很简单的,硬件性能实在是不足了,显存不停的溢出,两张2080ti目前来说的话还是实在是有点不太足够。没辙了,放弃了,等后面看着有更好的显卡再说吧。
现在折腾AI生成图像
使用Fooocus项目
github地址:https://github.com/lllyasviel/Fooocus
环境配置
conda create --name image python=3.10
git clone https://github.com/lllyasviel/Fooocus.git
cd Fooocus
conda env create -f environment.yaml
conda activate fooocus
pip install -r requirements_versions.txtconda activate fooocus
python entry_with_update.py --listen
#对于 Fooocus 动漫版使用python entry_with_update.py --preset anime或。现实版python entry_with_update.py --preset realistic当然网络问题是保留节目了
经常会卡在某一个环节如下所示
(image) yanchang@SDFMU3:~/DATA/AIimage/Fooocus$ python launch.py --preset realistic
[System ARGV] ['launch.py', '--preset', 'realistic']
Python 3.10.18 | packaged by conda-forge | (main, Jun 4 2025, 14:45:41) [GCC 13.3.0]
Fooocus version: 2.5.5
Loaded preset: /home/yanchang/DATA/AIimage/Fooocus/presets/realistic.json
[Cleanup] Attempting to delete content of temp dir /tmp/fooocus
[Cleanup] Cleanup successful
Downloading: "https://huggingface.co/lllyasviel/misc/resolve/main/xlvaeapp.pth" to /home/yanchang/DATA/AIimage/Fooocus/models/vae_approx/xlvaeapp.pth只需要一直用类似于下面的命令行代替每一个需要的模型,不会的可以找ai生成
wget -O /home/yanchang/DATA/AIimage/Fooocus/models/vae_approx/xlvaeapp.pth "https://huggingface.co/lllyasviel/misc/resolve/main/xlvaeapp.pth"
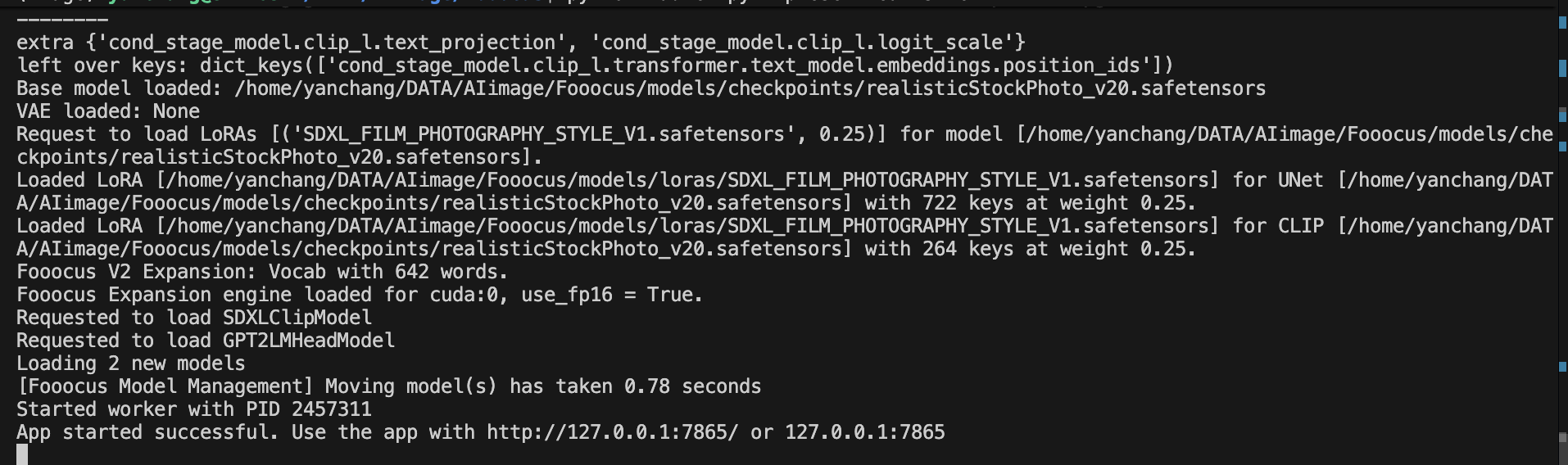
一直到如下,就可以打开网页端进行图像生成了
绕过安全审查
文件一、Fooocus/extras/safety_checker/models/safety_checker.py。复制后替换为
# from https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import numpy as np
import torch
import torch.nn as nn
from transformers import CLIPConfig, CLIPVisionModel, PreTrainedModel
from transformers.utils import logging
logger = logging.get_logger(__name__)
def cosine_distance(image_embeds, text_embeds):
normalized_image_embeds = nn.functional.normalize(image_embeds)
normalized_text_embeds = nn.functional.normalize(text_embeds)
return torch.mm(normalized_image_embeds, normalized_text_embeds.t())
class StableDiffusionSafetyChecker(PreTrainedModel):
config_class = CLIPConfig
main_input_name = "clip_input"
_no_split_modules = ["CLIPEncoderLayer"]
def __init__(self, config: CLIPConfig):
super().__init__(config)
self.vision_model = CLIPVisionModel(config.vision_config)
self.visual_projection = nn.Linear(config.vision_config.hidden_size, config.projection_dim, bias=False)
self.concept_embeds = nn.Parameter(torch.ones(17, config.projection_dim), requires_grad=False)
self.special_care_embeds = nn.Parameter(torch.ones(3, config.projection_dim), requires_grad=False)
self.concept_embeds_weights = nn.Parameter(torch.ones(17), requires_grad=False)
self.special_care_embeds_weights = nn.Parameter(torch.ones(3), requires_grad=False)
@torch.no_grad()
def forward(self, clip_input, images):
# 直接返回原始图像,所有图像都被认为是安全的
if torch.is_tensor(images):
batch_size = images.shape[0]
else:
batch_size = len(images)
has_nsfw_concepts = [False] * batch_size
return images, has_nsfw_concepts
@torch.no_grad()
def forward_onnx(self, clip_input: torch.Tensor, images: torch.Tensor):
# ONNX版本也同样处理
batch_size = images.shape[0]
has_nsfw_concepts = torch.tensor([False] * batch_size, device=images.device)
return images, has_nsfw_concepts文件二、Fooocus/extras/censor.py替换为以下内容
import os
import numpy as np
import torch
from transformers import CLIPConfig, CLIPImageProcessor
# 假设以下模块是您项目的一部分,并且可以正确导入
# 如果这些导入引发错误,请确保模块路径正确
import ldm_patched.modules.model_management as model_management
import modules.config
from extras.safety_checker.models.safety_checker import StableDiffusionSafetyChecker
from ldm_patched.modules.model_patcher import ModelPatcher
# 假设 __file__ 变量可用,如果作为独立脚本运行则没有问题
# 如果在交互式环境(如 Jupyter)中运行,您可能需要手动指定路径
try:
safety_checker_repo_root = os.path.join(os.path.dirname(__file__), 'safety_checker')
except NameError:
# 如果 __file__ 未定义,提供一个备用路径或当前工作目录
safety_checker_repo_root = os.path.join('.', 'safety_checker')
config_path = os.path.join(safety_checker_repo_root, "configs", "config.json")
preprocessor_config_path = os.path.join(safety_checker_repo_root, "configs", "preprocessor_config.json")
class Censor:
"""
一个审查类,用于检查图像是否包含不安全内容。
此类已被修改以禁用安全检查功能。
"""
def __init__(self):
"""初始化审查器实例变量。"""
self.safety_checker_model: ModelPatcher | None = None
self.clip_image_processor: CLIPImageProcessor | None = None
self.load_device = torch.device('cpu')
self.offload_device = torch.device('cpu')
def init(self):
"""
(此方法在修改后不再被调用)
原始功能:加载并初始化安全检查模型。
"""
if self.safety_checker_model is None and self.clip_image_processor is None:
safety_checker_model = modules.config.downloading_safety_checker_model()
self.clip_image_processor = CLIPImageProcessor.from_json_file(preprocessor_config_path)
clip_config = CLIPConfig.from_json_file(config_path)
model = StableDiffusionSafetyChecker.from_pretrained(safety_checker_model, config=clip_config)
model.eval()
self.load_device = model_management.text_encoder_device()
self.offload_device = model_management.text_encoder_offload_device()
model.to(self.offload_device)
self.safety_checker_model = ModelPatcher(model, load_device=self.load_device, offload_device=self.offload_device)
# ==================================================================
# 核心修改部分
# ==================================================================
def censor(self, images: list | np.ndarray) -> list | np.ndarray:
"""
无论输入什么,都直接返回原始图像。
这有效地禁用了安全检查功能。
"""
# 不执行任何检查,直接返回收到的图像
return images
# ==================================================================
# 创建 Censor 类的实例,并将其 censor 方法赋值给 default_censor
# 这样,其他地方调用 default_censor(...) 时,就会执行我们修改后的逻辑
default_censor = Censor().censor
搭配前几天的换脸,ok